
{kind=link}
Some relevant information about this subject is presented in the followings:
| Home Page | Overview | Site Map | Index | Appendix | Illustration | About | Contact | Update | FAQ |
|
There is no unanimous agreement on a theory about the origin of life. Any record would have been erased during the long history of turmoil on the Earth's surface. However, it is known that it must have happened between 4.5 - 3.7 billion years ago when the Earth's crust solidified and
flecks of bio-carbon (organisms favor C12 over C13) was found in Isua, Greenland. An artist's impression about the events leading to the origin of life and thereafter is drawn in Figure 11-01. Some relevant information about this subject is presented in the followings: |
Figure 11-01 Origin of Life |
only one place of constancy and nourishment - a warm spring in the relative safety of the deep ocean floor. It was the only habitable zone at that time for very simple life. |
 |
 |
|
Figure 11-02a Atmospheric Composition |
Figure 11-02b |
 |
The high water content in our body has suggested to many biologists that life on Earth arose in the oceans. In fact, there is a rough correspondence between the content of such elements as calcium and potassium in seawater and in blood and tissues. It is thought that living systems tend to incorporate the primitive environment, so that their internal surroundings would tend to resemble the familiar conditions of the early history of life, a possibility first glimpsed by the 19th century French physiologist Claude Bernard. |
Figure 11-03a Water |
 |
In 1953 Stanley Miller mixed substances such as water, molecular hydrogen, methane, and ammonia in a flask. After passing electrical discharge as input energy to this mixture, the assembly rearranged into a host of organic molecules as shown in Figure 11-03b including amino and nucleic acids - the building blocks of life. However, the result cannot be reproduced if carbon dioxide or molecular oxygen is added to the experiment (more specifically, it requires H/C  4/1). Since the experimental environment is not exactly the same as the atmosphere of the early Earth (note the presence of CO2), it could be that those organic molecules were 4/1). Since the experimental environment is not exactly the same as the atmosphere of the early Earth (note the presence of CO2), it could be that those organic molecules were
|
Figure 11-03b Prebiotic Chemistry |
produced in either localized spots on Earth where the chemical composition may be different from the global environment, or they might come from outer space. For example, the Murchison meteorite1 contains similar organic matter as produced in the experiment. |
 |
Note that glycine and alanine are the most abundant amino acids in both cases. They are the simplest amino acids produced by the most stable codons GGC and GCC (see genetic code). Recent research indicates that they are probably the earliest building blocks for life. Meanwhile, astronomers have detected more than 130 different kinds of organic molecules by 2005 in the giant molecular clouds where stars (and planets) are born. These range from the simple two-atom molecules such as nitric oxide (NO), to the large cyanopentacetylene (HC11N) with chain of 11 carbon atoms. By 2013, the number of molecular species found in space has increased to about 180 by various means of detection (Figure 11-03c). It is not known how some of the more complicated arrangements can be formed in the cold-dark inter-stellar space. One suggestion proposes quantum tunneling to overcome the energy barrier in the process of formation. |
Figure 11-03c Molecules in Space [view large image] |
 |
The materials of life can be summarized into one category - the reduced organic compounds. The process of reduction stores energy while the carbon in organic substance provides a versatile building block. There are many theories on the source of such materials, such as lightning in the atmosphere, and delivery by comets as discussed above. Another suggestion is from the hydrothermal vents located near the mid-ocean ridge. Hydrocarbons are produced when CO2 in ocean water meets H2 in the spring water from the mould (Figure 11-03d) according to the formula : CO2 (dissolved in water as HCO3-) + [2+(m/2n)]H2 It might not be coincident that similar kind of chemical process is still running in some modern prokaryotic autotrophs such as the methanogens (see more in "Hydrothermal Vents and the Origin of Life"). A more elaborate formula shows the production of a unit of proto-life as well as voluminous acetic acid and waste water from materials in the ocean and hot spring: |
Figure 11-03d Hydrothermal Mounds [view large image] |
{210CO2 + H2PO4- + Fe, Mn, Ni, Co, Zn2+}ocean + {427H2 + 10NH3 + HS-}hot spring {C70H129O65N10P (Fe, Mn, Ni, Co, Zn) S}proto-life + {70H3C  COOH + 219H2O}waste COOH + 219H2O}waste |
 |
 |
biological polymers (such as proteins and nucleic acids) without the assistance from the enzymes. But it has been shown that polymerization of amino acids can occur when exposed to dry heat. Another possible way around this problem is the use of inorganic catalysts such as the surface of some mineral or between layers of clay (Figure 11-03e) to perform the function. A 2010 study indicates that cyclic nucleotides (Figure 11-03f), which are a chemical variation of the nucleotides that make up RNA, will spontaneously link to each other and form viable RNA chains. Thus, if there were cyclic nucleotides in the primordial soup, catalyst was not needed to start life. It is further conjectured that such reactions were |
Figure 11-03e Clay Catalyst |
Figure 11-03f Cyclic Nucleotide |
more likely to occur in environments like the hydrothermal vents (Figure 11-03d). |

 |
 |
The oxidation and reduction always run in pair by the conservation of charge. Figure 11-03g shows a typical redox reaction in the form of cellular respiration via hydrogen exchange. Since the electron has higher mobility, it is not necessarily associated directly with the reactants. Figure 11-03h shows a recent study of H2S oxidization by bacteria in marine sediment. This reaction is coupled to the oxygen-reduction in the oxic layer (to form H2O) via rapid electron transfer (instead of hydrogen exchange). It is suggested that the bacteria mediate the electron flow either by the hair-like appendages or by some unknown conducting mechanism. Other examples include the electron transport on |
Figure 11-03g Redox Reaction, H Exchange |
Figure 11-03h Redox Reaction, e Transport |
cellular membrane, and electrons move through wire in battery even though the electrodes are separated. |
 G is a measure of the maximum work that can be obtained from a reaction. It is related to the difference in E0 before and after the reaction. Its value is positive for gaining energy in the case of oxidation, and negative implying infusion of energy in reduction such as the processes (1) and (2). The length of the arrows is proportional to G, but the reactions at the end points (of the arrow) are not related.
G is a measure of the maximum work that can be obtained from a reaction. It is related to the difference in E0 before and after the reaction. Its value is positive for gaining energy in the case of oxidation, and negative implying infusion of energy in reduction such as the processes (1) and (2). The length of the arrows is proportional to G, but the reactions at the end points (of the arrow) are not related.
 |
(1) Nitrogen Fixation - N2 + 8H+ + 8e+ (2) Sulfate Reduction - CH4 + SO42- (3) Anaerobic Sulfide Oxidation - 2H2S + O2 (4) Oxidation of Carbohydrate - CnH2nOn + nO2 (5) Aerobic Sulfide Oxidation - HS- + 2HCO3- + 3H+ (6) Aerobic Ammonia Oxidation - 4NH3 + 5O2 (7) Aerobic Iron Oxidation - 4Fe2+ + 4H+ + O2 |
Figure 11-03i Redox Reaction |
These reactions (except #4) are referred to as chemosynthesis used by primitive bacteria. |
 |
Recently (in the 2010s) it is realized that a lot of bacteria live inside animals (such as sponges, nematode worms, clams, ...) symbiotically. The animals provide the hydrogen sulphide (H2S) for the microbes as food via chemosynthesics (Figure 11-03j), the by-products of which supply them with necessary materials for life. It is suggested that our LCA (Last Common Ancestor) started out by utilizing the energy stored in the oxygen when it is combined with hydrogen to form water at the bottom of the redox scale extracting tiny amount of free energy from the environment (see Figure 11-03i, and h). Gradually through these chemical chain, bacteria evolved by taking in various inorganic or organic matters for the maintenance of life. Eventually, photosynthesis was invented to produce a more efficient energy storage via the carbohydrates. The toxic oxygen giving off in this process was finally overcome by oxygen respiration. With the accomplishment of these feats, the dwelling place on Earth is changed forever. Figure 11-03i shows that energy is available for transfer down the redox gradients whenever there is an energy source (such as the |
Figure 11-03j Chemosynthesis |
hydrothermal mounds or rotting organic matter) to pump the electron up the chain initially, and the materials for life do not depend on oxygen or water or light exclusively. This is especially relevant to the search for life in other planets. |
 |
It is discovered in 2010 off the south coast of Greece that there are multicellular animals (metazoans) living all their life in anoxic environments. The species belong to a phylum of tiny bottom-dwellers call Loricifera (Figure 11-03k). Measuring less than 1 mm long, they live at a depth of more than 3000 meters in the anoxic sediments of the Atalante basin - a place seems to be habitable only for bacteria. The Loricifera generates energy from hydrogen sulphide (H2S) using organelles called hydrogenosomes, which it is believed to evolve from mitochondria. Other more primitive bacteria manage to eke out a meagre existence 10 km below sea level on seabed. Their very slow living is maintained by combining sulphate ions (from the rock) with free hydrogen (from water split by uranium decay radiation) through a process called radiolysis§. Such discoveries imply that life could be everywhere in the Solar system and beyond. |
Figure 11-03k Loricifera [view large image] |
 |
Advocates of Intelligent Design used to ridicule evolution theory by the analogy of "tornado in a junkyard" that assembles a 747 airplane from scraps at one fell swoop. However, evolution uses a huge number of incremental steps to go from something simple to something complex as exemplified by the steps in Figure 11-04a in which each step is subjected to natural selection; and while the goal in the analogy is to produce a |
Figure 11-04a Transition from Nonlife to Life [view large image] |
jumbo jet, evolution has no goal - it selects for what's operable now, not for what might become useful in the future. Having said that, although there are plenty of circumstantial |
 |
|
Figure 11-04b Mineral Greigite [view large image] |
 |
polymers and render a cluttered product. The results of thirty years of intensive chemical experimentation have shown that the prebiotic synthesis of amino acids is easy to simulate in a reducing environment (meaning the composition does not contain oxygen or hydrogen is present in the composition), but the prebiotic synthesis of nucleotides is difficult in all environments. It is suggested that the first RNA may be created from the ATP molecules, which were readily available in hydrothermal vents. They linked together to form the very simple genetic code AAA, which still encodes the amino acid lysine today. Figure 11-04c shows the synthesis of peptide chain by a short piece of RNA triplet of A, U, G locating on a mineralized iron sulfide surface in the absence of transfer RNA (the mechanism for specificity in modern organisms). In the diagram, the RNA grips part of the amino acid methionine at the center and offers it to an adjacent amino acid at the left. |
Figure 11-04c Primitive RNA [view large image] |
 |
Various substances can be incorporated into the droplet until the right mixture is acquired to start up metabolism and reproduction. A novel process involves the synthesis of membrane at the inner surface of iron sulfide bubble around alkaline vents. The proteinaceous membrane eventually escaped from the iron sulfide incubator with RNA and peptide inside to become the proto-acetogens and proto-methanogens - the microbes generating waste of acetate (ionic acetic acid) and methane respectively (Figure 11-4d). |
Figure 11-04d Membrane, Primitive [view large image] |
 |
|
Figure 11-04e Origin of Life Theories |
(2) the molecules join together by chance in chains, some of which are capable of reproducing themselves, (3) these chains make many copies of themselves, (4) sometimes forming mutant versions that are also capable of replicating, (5) mutant replicators that are better adapted to the environment |
 |
 |
The RNA world postulates that in the beginning the RNA molecules also performed the catalytic activities necessary to replicate themselves from a nucleotide soup. The RNA molecules evolved in this self-replicating patterns, using recombination and mutation to explore new niches. They then developed an entire range of enzymic activities. At the next stage, RNA molecules began to synthesize the first proteins, which would simply be better enzymes than their RNA counterparts. Finally, DNA appeared on the scene, the ultimate holder of information copied from the genetic RNA molecules by reverse transcription. RNA is then relegated to the intermediate role it has today - no longer at the center of the stage, displaced by DNA and the more effective protein |
Figure 11-04f RNA World, Older Version |
Figure 11-04g1 RNA World, Updated Version |
enzymes. Figure 11-04f is a schematic depiction of the RNA world, while Figure 11-04g1 presents the RNA world evolution in a series of pictures. See "RNA folding" for its special characteristic. |
 |
feasibility. One of the containers in the experiment holds a liquid that mimics the oceans of the early Earth. The water is rich in carbon dioxide and iron, has a pH of 5.5 and is held at room temperature. The other container is heated to 130oC, and its water is laden with hydrogen and sulphide with a Ph of 11. This second fluid is meant to stand in for the hot waters that spewed out of ocean-bottom springs early in the Earth's history. The liquids mix in a chrome steel pressure barrel containing a catalyst of iron and nickel sulphide. It is supposed to be the pores within the "chimneys" near the ocean hot springs. The gels in the chimneys act as membranes allowing small molecules such as nutrients and wastes to pass through but keeping the macro-molecules such as proteins inside. His goal is to demonstrate that the |
Figure 11-04g2 Origin of Life Experiment |
experiment can produce amino acids and peptides. He has yet to reproduce life's first steps of making simple organic molecules like methane and acetate. |
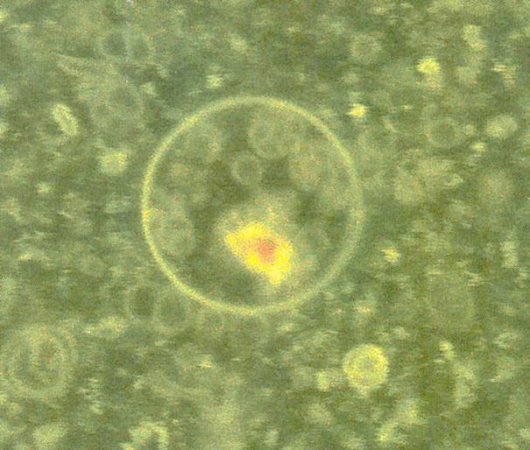 |
themselves into RNA, which is then automatically trapped inside the fatty acid bubbles. The result is something that resembles a cell: It has genetic material and water contained within a waterproof fatty-acid pouch. Figure 11-04h is an image of these makeshift cells taken with an optical microscope and enhanced using fluorescent dye, it reveals yellow bits of RNA inside spherical green vesicles. They have not created life yet. It will be their next step to assemble a system of ribozyme, RNA and vesicle. This system has to grow, divide, and evolve in order to make the transition to life. Once there's one example of a lab system that's evolving by itself, then the challenge is to build systems that can evolve under different conditions such as the high-pressure liquid hydrogen in Jupiter and Saturn. By the summer of 2007, Jack Szostak predicts that within the next six months, scientists will be able to create a cell membrane using fatty acids. |
Figure 11-04h Proto-cell |
He is also optimistic about getting nucleotides to form a working genetic system. The idea is that once the container is made, if scientists add nucleotides in the right proportions, then Darwinian evolution could simply take over. A June 2008 publication by him indicates that early proto-cells |
 |
The experiment of making organic molecules out of inorganic substances by Stanley Miller in 1953 is not his only origin of life investigation (Figure 11-04j). He had also filled a batch of vials in 1972 with a mixture of water (H2O), ammonia (NH3) and cyanide (any chemical compound containing the cyano group - C N), chemicals that scientists believe existed on early Earth and may have contributed to the rise of life. He had then cooled the mixture to the temperature of Jupiter's icy moon Europa (~ -170oC). Most scientists believe that it is too cold for much of anything to happen. Examination of the vials in his laboratory at the University of California at San Diego 25 years later in 1997 reveals that the normally colorless mixture had deepened to amber (Figure 11-04i) indicating the presence of complex polymers made up of organic molecules. Tests later confirmed that the mixture had coalesced into the molecules of life: nucleotides, the building blocks of RNA and DNA, and amino acids, the building blocks of proteins. It turns out that the microscopic pockets of liquid within the ice increase N), chemicals that scientists believe existed on early Earth and may have contributed to the rise of life. He had then cooled the mixture to the temperature of Jupiter's icy moon Europa (~ -170oC). Most scientists believe that it is too cold for much of anything to happen. Examination of the vials in his laboratory at the University of California at San Diego 25 years later in 1997 reveals that the normally colorless mixture had deepened to amber (Figure 11-04i) indicating the presence of complex polymers made up of organic molecules. Tests later confirmed that the mixture had coalesced into the molecules of life: nucleotides, the building blocks of RNA and DNA, and amino acids, the building blocks of proteins. It turns out that the microscopic pockets of liquid within the ice increase |
Figure 11-04i Life from Ice |
the concentration of the primordial soup causing the reaction rate to go up. But it was suspected that the "growth" is the result of contamination. Since then other experiments on formation of new strand of RNA, and creating RNA out of individual nucleotides had been successful under such cold environment. |
 |
Thus, the idea is influencing not just theories about life's origin on Earth but the possibility of life on Europa, Enceladus, and Titan is now more relevant than ever. Shortly after Miller finished his 25-year experiment, he suffered a stroke that ended his career. His laboratory, with 40 years of samples, was emptied in 2002 to make way for a building renovation. Experiments that had run for years or decades were discarded without ever being analyzed. Only a few items from the freezer had been rescued, the rest were incinerated for fear of cyanide poisoning. Miller was present for a few hours of this ordeal, struggling to find words to identify the vials that he had known so well. He died on May 20, 2007. |
Figure 11-04j Stanley Miller [view large image] |
 |
Since then the idea of life starting in ice has inspired further investigations both out in the field north of the Arctic Circle and in the laboratories. These works provide better understandings about chemical reactions within the tiny pockets of water insider the ice (Figure 11-04k). However, this theory should not be considered as the only one in exclusion of the others. Glaciers on early Earth could have scooped up mineral dust; volcanoes could have rained ash onto nearby sea ice. Primordial ice must have been full of impurities with some organic compounds already. |
Figure 11-04k Ice Catalyst |
Followings are some novel properties about the icy environment as published in a special issue (in Summer 2011) on "Evolution" by the Discover Magazine. |
 |
 |
in kick-start key chemical reactions at the very beginning. As illustrated in Figure 11-04m, synthesis of nucleotide into chain can be destroyed by the reverse reaction of hydrolysis unless the water molecules are removed from the environment. Such environment could be realized exactly with the drying of the clay, while more nucleotides would be added in the wetting cycle. Result on one field trip reveals that chains of RNA may have grown |
Figure 11-04l Life in Mud Pool |
Figure 11-04m Formation of Polymer [view large image] |
wrapped in blankets on concentrated sulphuric acid (in the volcanic mud), which helps to suck water molecules out of the primordial soup. |
 |
Meanwhile on Earth, there are bacteria which can survive very harsh condition on another planet. In an Earth lab, Deinococcus radiodurans (D. rad) can withstand extreme levels of radiation, extreme temperatures, dehydration, and exposure to genotoxic chemicals. They even have the ability to repair their own DNA, usually within 48 hours. Known as an extremophile, bacteria such as D. rad are of interest to NASA partly because they might be adaptable to help human astronauts survive on other worlds. A recent map of D. rad's DNA might allow biologists to augment their survival skills with the ability to produce medicine, clean water, and oxygen. Already they have been genetically engineered to help clean up spills of toxic mercury. Likely one of the oldest surviving life forms, D. rad was discovered by accident in the 1950s when scientists investigating food preservation techniques could not easily kill it. In Figure 11-04n Deinococcus radiodurans grow quietly in a petri dish. |
Figure 11-04n Bacteria, |
 |
According to Arch Mission, there would be no chance for the tardigrades to contaminate the Moon since it has no water to revive the little bugs even if they manage to get out of the enclosure somehow. That could be exactly the situation with the Beresheet crash-landing although they maintain that the library should be intact. An interesting case arises if in the next million or billion years, an ice-bearing comet hit the Moon near the crash site. The impact will melt the epoxy resins releasing the plucky tardigrades which will then flourish and turns into some kind of indestructible monster ... |
Figure 11-04o Tardigrades on Moon |
It is a nice plot for science fiction or is it how multicelluar life began on Earth? i.e., via delivery from another world triggering the Cambrian Explosion. |
 |
Analysis of tardigrade's genome in 2016 reveal an unique sequence expressing the Damage suppressor protein (Dsup), which is present only in tardigrades. Further research indicates that Dsup binds to nucleosomes and protects DNA from hydroxyl radicals as well as high energy radiation. Genetically modified human cells to express Dsup also safeguards against damage from X-rays (Figure 11-04oa). It turns out that the Dsup forms a cloud-like structure; the cloud surrounds the DNA's chromatin envelope, blocking hydroxyl radicals and preventing them from disrupting cellular DNA (see insert), it works on free DNA as well. Computer simulation of Dsup in complex with DNA shows that it is an intrinsically disordered protein. Its flexibility and electrostatic charge helps it bind to DNA and from aggregates. |
Figure 11-04oa Tardigrade, Protection by Dsup [view large image] |
Right now, the main applications are in pharmaceuticals and crop plants. Other possibilities include cancer treatment, and space traveling. |
 |
|
Figure 11-04ob Tardigrade |
See  |

 |
several essential roles in cells: it maintains the structure of DNA and RNA, combines with lipids to make cell membranes and transports energy within the cell through the macro-molecule ATP. Many science-fictions portray alternate life-forms using silicon instead of carbon, but this discovery marks the first known case in a real organism. However, rigour scientific method demands that the researchers should demonstrate the presence of arsenic not just in the microbial cells, but in specific biomolecules within them. Such requirement would take much more work to satisfy. It is also known that arsenate forms |
Figure 11-04p Arsenic Bacteria |
much weaker bonds in water than phosphate. It breaks apart on the order of minutes. Thus they should also explain how to stabilize the AsO43- structure in such circumstance. |
 |
Further scrutiny of the arsenic data indicates that the microbe is not using the arsenic, but instead is scavenging every possible phosphate molecule while fighting off arsenic toxicity. As shown in Figure 11-04q, the cell's large vacuoles may be their way of sequestering the arsenic. It is also noted that the cells grown in high concentrations of arsenate did not seem to contain any RNA - possibly because RNA production had shut down to conserve phosphate. |
Figure 11-04q Arsenic Vacuoles |
As Christmas 2010 approaching, the authors of the original paper finally response to criticism by posting their supporting evidences online. One of the authors also appears in an interview to express her personal feeling about the pressure created by all the furies. |
 |
 |
 |
Such field is thriving with more funding from various agents. The Synthetic Biology Journal started publication in 2016, and researchers from 17 laboratories in the Netherlands formed the group Building a Synthetic Cell (BaSyC), which aims to construct a �cell-like, growing and dividing system� within ten years. |
Figure 11-04r Synthetic Life |
Figure 11-04s Synthetic Membrance [view large image] |
Figure 11-04t Incorporation of Proteins [view large image] |
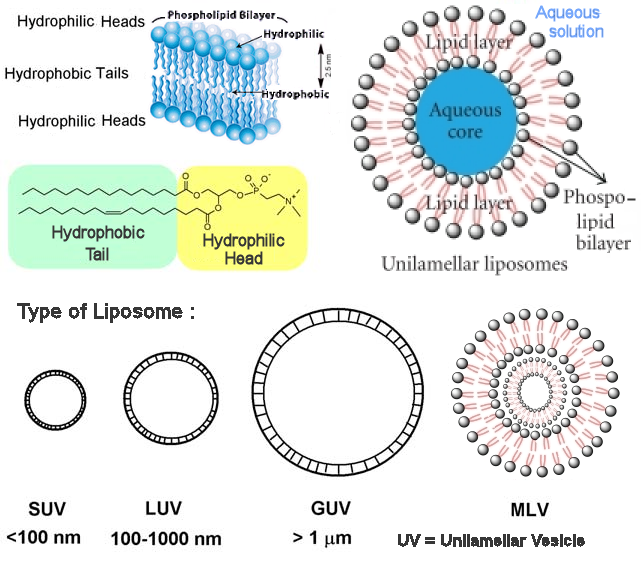 |
|
Figure 11-04u Cell Membrance |
BTW, microfluidics chip is used to study the behaviour of fluids through micro-channels. |
 |
|
Figure 11-04v A Bag of Chemicals |
Other example involves encapsulating the motor protein kinesin and the microtubule to produce a force-generating network that can propel the movement of the vesicle. |
 |
Bioreactor is the fancy name for the process of fementation (Figure 11-04x). While bacteria are used to make cheese for hundreds of years, the modern version uses them to produce biochemicals for drug, sewage treatment, tissue engineering, ... A side benefit in the search for synthetic life is the discovery that by introducing genetic circuits into the liposomes, new proteins can be produced to provide novel solutions for treating cancer, tackling antibiotic resistance or cleaning up toxic sites, ... |
Figure 11-04x Bioreactor |
 |
 |
controls can easily be incorporated into the process or a kill switch can be installed to render the things harmless. Anyway, Figure 11-04z shows the trailer of a 1969 movie: "The Andromeda Strain" (Andromeda stands for "A" - the first case of outer space attack, the microbes are not from Andromeda) in which a satellite brought back deadly microbes from outer space ... |
Figure 11-04y Crossota Millsae |
Figure 11-04z Andromeda Strain |
1The Murchison meteorite was recovered in Australia in 1969. Analysis of the meteorite found over 90 types of amino acids as well as some left-handed sugar that does not exist naturally on Earth. This rare form of substance tends to prove the extraterrestrial origin of the rest of the contents. The Murchison meteorite contains the same amino acids obtained by Stanley Miller in his laboratory, and even in the same relative proportions
2Metabolism is the sum of all chemical activities occurring inside a living cell. Metabolic cycle (pathway) begins with a particular reactant and terminate with an end product.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}